KOKKOS with OpenMP
Overview
Teaching: 30 min
Exercises: 15 minQuestions
How do I utilise KOKKOS with OpenMP
Objectives
Utilise OpenMP and KOKKOS on specific hardware
Be able to perform a scalability study on optimum command line settings
Using OpenMP threading through the KOKKOS package
In this episode, we’ll be learning to use KOKKOS package with OpenMP execution for multi-core CPUs. First we’ll get familiarized with the command-line options to run a KOKKOS OpenMP job in LAMMPS. This will be followed by a case study to gain some hands-on experience to use this package. For the hands-on part, we’ll take the same rhodopsin system which we have used previously as a case study. We shall use the same input file and repeat similar scalability studies for the mixed MPI/OpenMP settings as we did it for the USER-OMP package.
Factors that can impact performance
- Know your hardware: get the number of physical cores per node available to you. Take care such that
(number of MPI tasks) * (OpenMP threads per task) <= (total number of physical cores per node)- Check for hyperthreading: Sometimes a CPU splits its each physical cores into multiple virtual cores. Intel’s term for this is hyperthreads (HT). When hyperthreading is enabled, each physical core appears as (usually) two logical CPU units to the OS and thus allows these logical cores to share the physical execution space. This may result in a ‘slight’ performance gain. So, a node with 24 physical cores appears as 48 logical cores to the OS if HT is enabled. In this case,
(number of MPI tasks) * (OpenMP threads per task) <= (total number of virtual cores per node)- CPU affinity: CPU affinity decides whether a thread running on a particular core is allowed to migrate to another core (if the operating system thinks that is a good idea). You can set CPU affinity masks to limit the set of cores that the thread can migrate to, for example you usually do not want your thread to migrate to another socket since that could mean that it is far away from the data it needs to process and could introduce a lot of delay in fetching and writing data.
- Setting OpenMP Environment variables:
OMP_NUM_THREADS,OMP_PROC_BIND,OMP_PLACESare the ones we will touch here:
OMP_NUM_THREADS: sets the number of threads to use for parallel regionsOMP_PROC_BIND: set the thread affinity policy to be used for parallel regionsOMP_PLACES: specifies on which CPUs (or subset of cores of a CPU) the threads should be placed
Command-line options to submit a KOKKOS OpenMP job in LAMMPS
In this episode, we’ll learn to use KOKKOS package with OpenMP for multi-core CPUs. To run the KOKKOS package, the following three command-line switches are very important:
-k on: This enables KOKKOS at runtime-sf kk: This appends the “/kk” suffix to KOKKOS-supported LAMMPS styles-pk kokkos: This is used to modify the default package KOKKOS options
To invoke the OpenMP execution mode with KOKKOS, the -k on switch takes additional
arguments for hardware settings as shown below:
-k on t Nt: Using this switch you can specify the number of OpenMP threads,Nt, that you want to use per node. You should also set a proper value for your OpenMP environment variables. You can do this withexport OMP_NUM_THREADS=4if you like to use 4 threads per node (
Ntis 4). Using this environment variable allows you to use-k on t $OMP_NUM_THREADSon the command line or in your job scripts.You should also set some other environment variables to help with thread placement. Good default options with OpenMP 4.0 or later are:
export OMP_PROC_BIND=spread export OMP_PLACES=threads
Get the full command-line
Try to create a job script to submit a LAMMPS job for the rhodopsin case study) such that it invokes KOKKOS with OpenMP threading to accelerate the job using 2 nodes, 2 MPI ranks per node with half the available cores on a node used as OpenMP threads per rank, and the default package options.
Solution
#!/bin/bash -x # Ask for 1 nodes of resources for an MPI/OpenMP job for 5 minutes #SBATCH --account=ecam #SBATCH --nodes=1 #SBATCH --output=mpi-out.%j #SBATCH --error=mpi-err.%j #SBATCH --time=00:10:00 # Let's use the devel partition for faster queueing time since we have a tiny job. # (For a more substantial job we should use --partition=batch) #SBATCH --partition=devel # Make sure that the multiplying the following 2 gives ncpus per node (24) #SBATCH --ntasks-per-node=2 #SBATCH --cpus-per-task=12 # Prepare the execution environment module purge module use /usr/local/software/jureca/OtherStages module load Stages/Devel-2019a module load intel-para/2019a module load LAMMPS/3Mar2020-Python-3.6.8-kokkos # Also need to export the number of OpenMP threads so the application knows about it export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK # Set some pinning hints as well export OMP_PROC_BIND=spread export OMP_PLACES=threads # srun handles the MPI task placement and affinities based on the choices in the job script file srun lmp -in in.rhodo -k on t $OMP_NUM_THREADS -sf kkA solution including affinity using the OpenMPI MPI would include runtime binding mechanisms like
--bind-to socketand--map-by socketwhich ensures that OpenMP threads cannot move between sockets (but how something like this is done is dependent on the MPI runtime used).OMP_PROC_BINDandOMP_PLACESwould then influence what happens to the OpenMP threads on each socket.
Finding out optimum command-line settings for the package command
There is some more work to do before we can jump into a thorough scalability study when
we use OpenMP in KOKKOS which comes with a few extra package arguments and
corresponding keywords (see the
previous episode for
a list of all options) as compared to that offered by the USER-OMP package. These
are neigh, newton, comm and binsize. The first thing that we need to do here is to
find what values of these keywords offer the fastest runs. Once we know the optimum
settings, we can use them for all the runs needed to perform the scalability studies.
In the last exercise, we constructed a command-line example to submit a LAMMPS job with
the default
package setting for the KOKKOS OpenMP run. But, often the default package setting
may not provide the fastest runs. Before jumping to production runs, we should investigate
other settings for these values to avoid wastage of our time and valuable
computing resources. In the next section, we’ll be showing how to do this with
rhodopsin example. An example of a set of command line arguments which shows
how these package related keywords can be invoked in your LAMMPS run would be
-pk kokkos neigh half newton on comm no.
The optimum values of the keywords
Using the rhodopsin input files (
in.rhodoanddata.rhodoas provided in the rhodopsin case study), run LAMMPS jobs for 1 OpenMP thread on 1 node using the following two set of parameters for thepackagecommand:
neigh full newton off comm noneigh half newton on neigh half comm host
What is the influence of
comm? What is implied in the output file?What difference does switching the values of
newton/neighhave? Why?Results obtained from a 40 core system
For a HPC setup which has 40 cores per node, the runtimes for all the MPI/OpenMP combinations and combination of keywords is given below:
neigh newton comm binsize 1MPI/40t 2MPI/40t 4MPI/10t 5MPI/8t 8MPI/5t 10MPI/4t 20MPI/2t 40MPI/1t full off no default 172 139 123 125 120 117 116 118 full off host default 172 139 123 125 120 117 116 118 full off dev default 172 139 123 125 120 117 116 119 full on no default 176 145 125 128 120 119 116 118 half on no default 190 135 112 119 103 102 97 94
The influence on
commcan be seen in the output file, as it prints the following;WARNING: Fixes cannot yet send data in KOKKOS communication, switching to classic communication (src/KOKKOS/comm_kokkos.cpp:493)This means the fixes that we are using in this calculation are not yet supported in KOKKOS communication and hence using different values of the
commkeyword makes no difference.Switching on
newtonand usinghalfneighbour list make the runs faster for most of the MPI/OpenMP settings. Whenhalfneighbour list and OpenMP is being used together in KOKKOS, it uses data duplication to make it thread-safe. When you use relatively few numbers of threads (8 or less) this could be fastest and for more threads it becomes memory-bound (since there are more copies of the same data filling up RAM) and suffers from poor scalability with increasing thread-counts. If you look at the data in the above table carefully, you will notice that using 40 OpenMP threads forneigh=halfandnewton=onmakes the run slower. On the other hand, when you use only 1 OpenMP thread per MPI rank, it requires no data duplication or atomic operations, hence it produces the fastest run.So, we’ll be using
neigh half newton on comm hostfor all the runs in the scalability study below.
Rhodopsin scalability study with KOKKOS
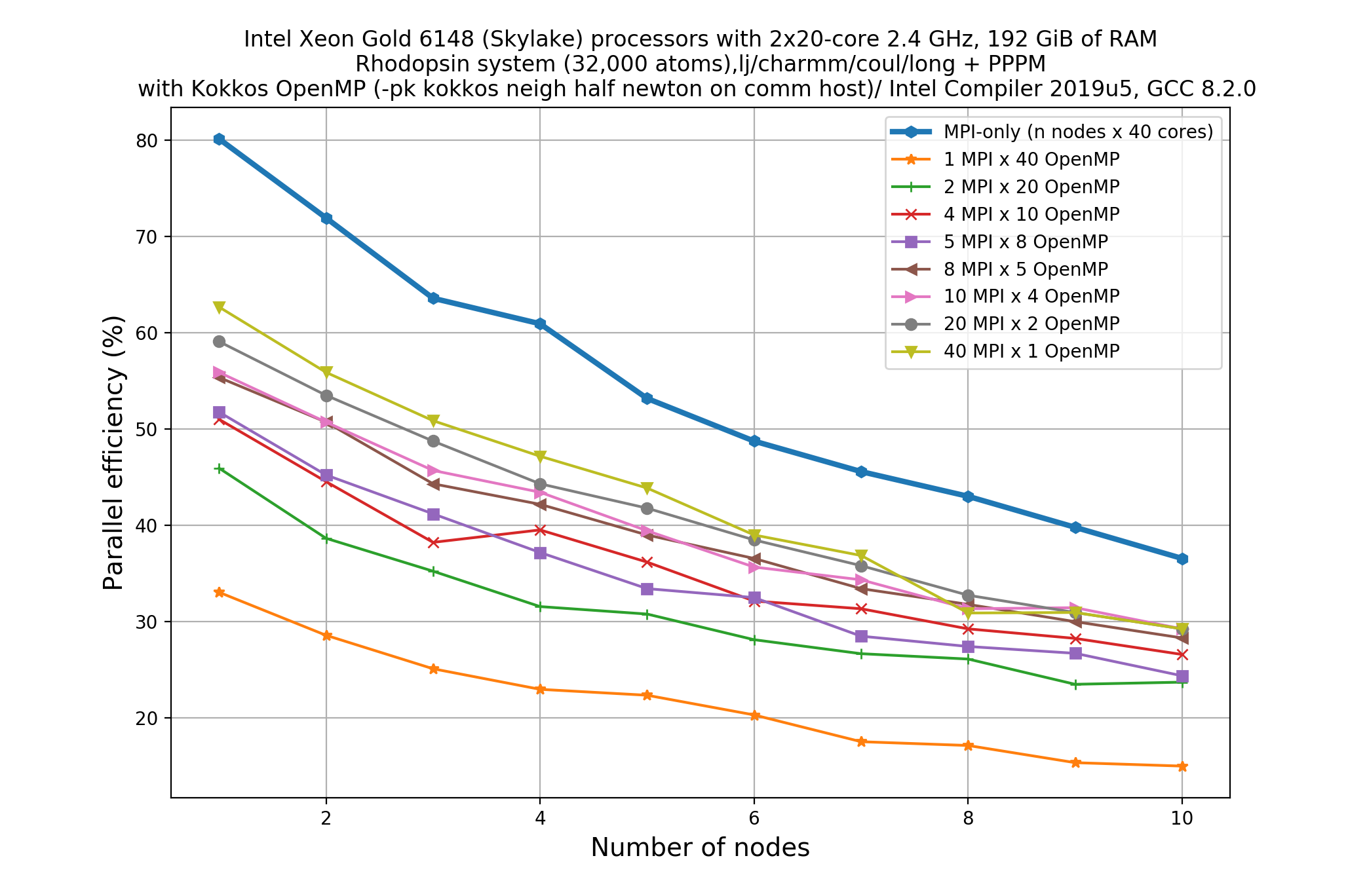
Doing a scalability study would be a time consuming undertaking, a full study would again require a total of 80 calculations for 10 nodes. Below is the result of such a study on an available system (FIX SCALES)
Compare this plot with the plot given in a previous exercise. Write down your observations and make comments on any performance “enhancement” when you compare these results with the pure MPI runs.
Solution
Data for the pure MPI-based run is plotted with the thick blue line. Strikingly, none of the KOKKOS based MPI/OpenMP mixed runs show comparable parallel performance with the pure MPI-based approach. The difference in parallel efficiency is more pronounced for less node counts and this gap in performance reduces slowly as we increase the number of nodes to run the job. This indicates that to see comparable performance with the pure MPI-based runs we need to increase the number of nodes far beyond than what is used in the current study.
If we now compare the performance of KOKKOS OpenMP with the threading implemented with the USER-OMP package, there is quite a bit of difference.
This difference could be due to vectorization. Currently (version
7Aug19or3Mar20) the KOKKOS package in LAMMPS doesn’t vectorize well as compared to the vectorization implemented in the USER-OMP package. USER-INTEL should be even better than USER-OMP at vectorizing if the styles are supported in that package.The ‘deceleration’ is probably due to KOKKOS and OpenMP overheads to make the kernels thread-safe.
If we just compare the performance among the KOKKOS OpenMP runs, we see that parallel efficiency values are converging even for more thread-counts (1 to 20) as we increase the number of nodes. This is indicative that KOKKOS OpenMP scales better with increasing thread counts as compared to the USER-OMP package.
Key Points
The three command line switches,
-k on,-sf kkand-pk kokkosare needed to run the KOKKOS packageDifferent values of the keywords
neigh,newton,commandbinsizeresult in different runtimes