Connecting performance to hardware
Overview
Teaching: 15 min
Exercises: 5 minQuestions
How can I use the hardware I have access to?
What is the difference between OpenMP and MPI?
How can I use GPUs and/or multiple nodes?
Objectives
Differentiate between OpenMP and MPI
Accelerating performance
To speed up a calculation in a computer you can either use a faster processor or use multiple processors to do parallel processing. Increasing clock-speed indefinitely is not possible, so the best option is to explore parallel computing. Conceptually this is simple: split the computational task across different processors and run them all at once, hence you get the speed-up.
In practice, however, this involves many complications. Consider the case when you are having just a single CPU core, associated RAM (primary memory: faster access of data), hard disk (secondary memory: slower access of data), input (keyboard, mouse) and output devices (screen).
Now consider you have two or more CPU cores, you would notice that there are many things that you suddenly need to take care of:
- If there are two cores there are two possibilities: Either these two cores share the same RAM (shared memory) or each of these cores have their own RAM (private memory).
- In case these two cores share the same RAM and write to the same place at once, what would happen? This will create a race condition and the programmer needs to be very careful to avoid such situations!
- How to divide and distribute the jobs among these two cores?
- How will they communicate with each other?
- After the job is done where the final result will be saved? Is this the storage of core 1 or core 2? Or, will it be a central storage accessible to both? Which one prints things to the screen?
Shared memory vs Distributed memory
When a system has a central memory and each CPU core has a access to this memory space it is known as a shared memory platform. However, when you partition the available memory and assign each partition as a private memory space to CPU cores, then we call this a distributed memory platform. A simple graphic for this is shown below:
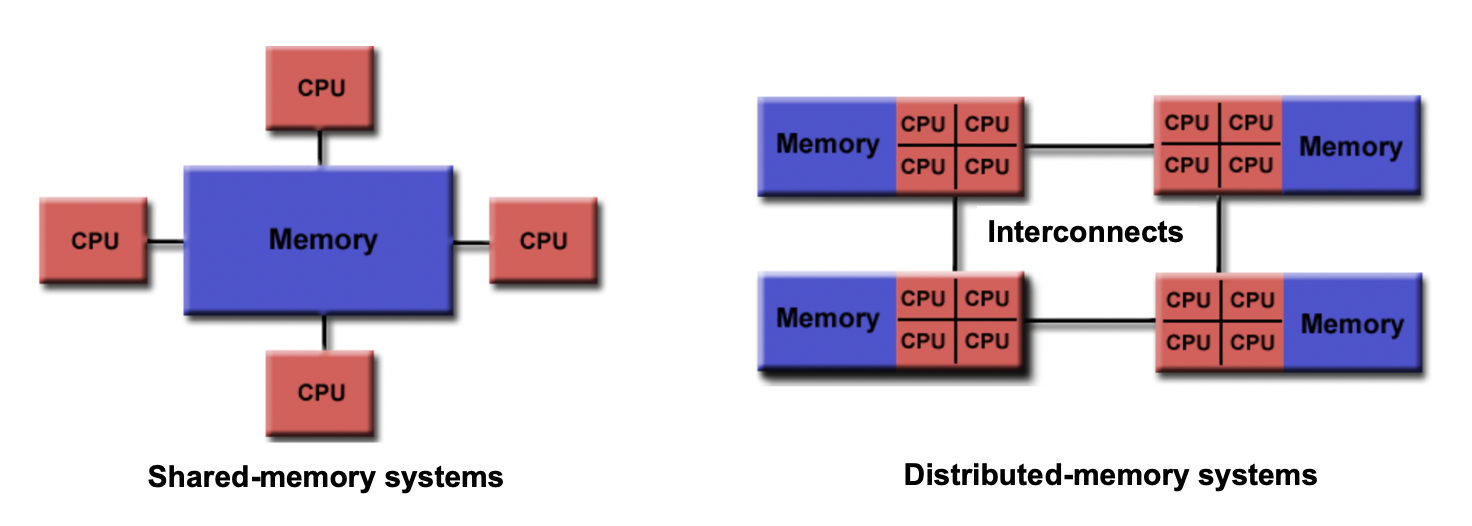
Depending upon what kind of memory a computer has, the parallelization approach of a code could vary. For example, in a distributed memory platform, when a CPU core needs data from its private memory, it is fast to get it. But, if it requires access to a data that resides in the private memory of another CPU core then it requires a ‘communication’ protocol and data access becomes slower.
Similar situation arises for GPU coding too. In this case, the CPU is generally called the host and the GPUs are called the devices. When we submit a GPU job, it is launched in the CPU (host) which in turn directs it to be executed by the GPUs (devices). While doing these calculations, data is copied from CPU memory to the GPU’s and then processed. After the GPU finishes a calculation, the result is copied back from the GPU to CPU. This communication is expensive and it could significantly slow down a calculation if care is not taken to minimize it. We’ll see later in this tutorial that communication is a major bottleneck in many calculations and we need to devise strategies to reduce the related overhead.
In shared memory platforms, the memory is being shared by all the processors. In this case, the processors communicate with each other directly through the shared memory…but we need to take care that the access the memory in the right order!
Parallelizing an application
When we say that we parallelize an application, we actually mean we devise a strategy that divides the whole job into pieces and assign each piece to a worker (CPU core or GPU) to help solve. This parallelization strategy depends heavily on the memory structure. For example, if we want to use OpenMP, it provides a thread level parallelism that is well-suited for a shared memory platform, but you can not use it in a distributed memory system. For a distributed memory system, you need a way to communicate between workers (a message passing protocol), like MPI.
Multithreading
If we think of a process as an instance of your application, multithreading is a shared memory parallelization approach which allows a single process to contain multiple threads which share the process’s resources but work relatively independently. OpenMP and CUDA are two very popular multithreading execution models that you may have heard of. OpenMP is generally used for multi-core/many-core CPUs and CUDA is used to utilize threading for GPUs.
The two main parallelization strategies are data parallelism and task parallelism. In data parallelism, some set of tasks are performed by each core using different subsets of the same data. Task parallelism is when we can decompose the larger task into multiple independent sub-tasks, each of which we then assign to different cores. A simple graphical representation is given below:
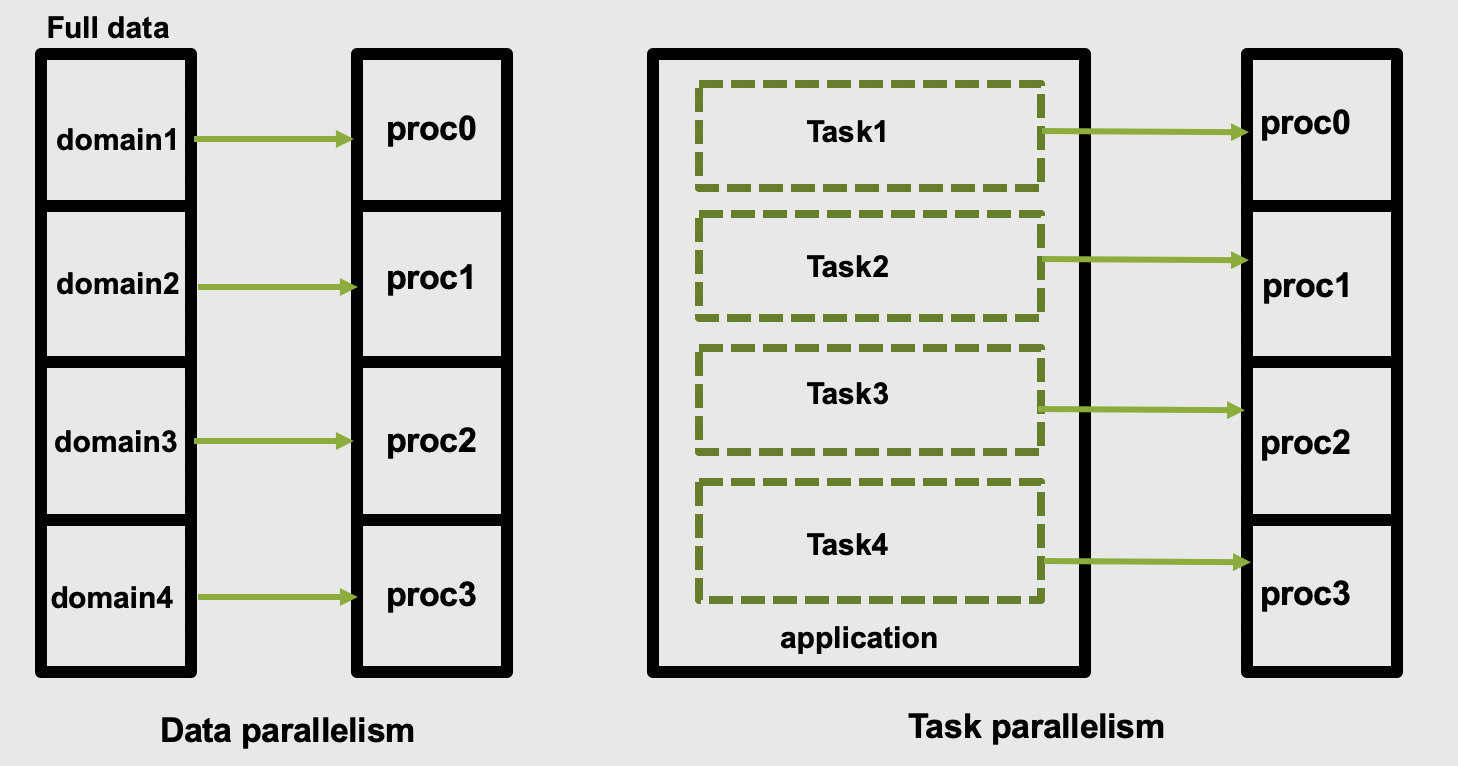
As application users, we need to know if our application actually offers control over which parallelization methods (and tools) we can use. If so, we then need to figure out how to make the right choices based on our use case and the hardware we have available to us.
Popular parallelization strategies
Data parallelism is conceptually easy to map to distributed memory, and it is the most commonly found choice on HPC systems. The main parallelization technique one finds is the domain decomposition method. In this approach, the global domain is divided into many sub-domains and then each sub-domain is assigned to a processor.
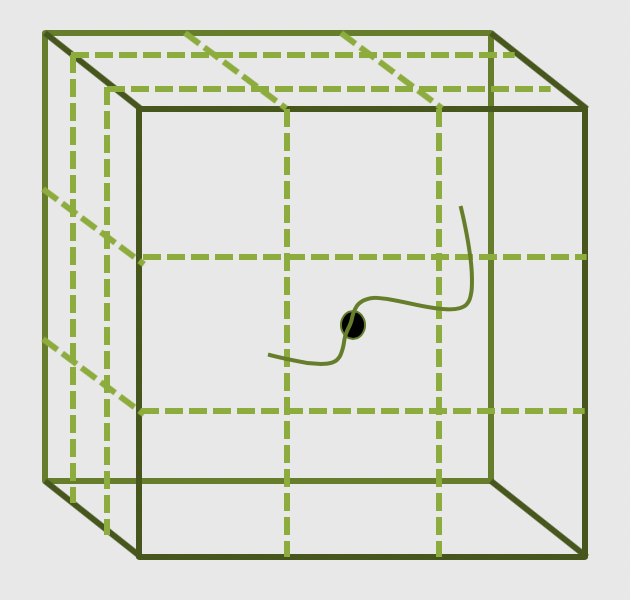
If your computer has N physical
processors, you could initiate
N MPI processes on your computer. This means each sub-domain is handled by an MPI process
and usually the domains communicate with their “closest” neighbours to exchange information.
What is MPI?
A long time before we had smart phones, tablets or laptops, compute clusters were already around and consisted of interconnected computers that had about enough memory to show the first two frames of a movie (2 x 1920 x 1080 x 4 Bytes = 16 MB). However, scientific problems back than were demanding more and more memory (as they are today). To overcome the lack of adequate memory, specialists from academia and industry came up with the idea to consider the memory of several interconnected compute nodes as one. They created a standardized software that synchronizes the various states of memory through the network interfaces between the client nodes during the execution of an application. With this performing large calculations that required more memory than each individual node can offer was possible.
Moreover, this technique of passing messages (hence Message Passing Interface or MPI) on memory updates in a controlled fashion allow us to write parallel programs that are capable of running on a diverse set of cluster architectures.(Reference: https://psteinb.github.io/hpc-in-a-day/bo-01-bonus-mpi-for-pi/ )
In addition to MPI, some applications also support thread level parallelism (through, for example OpenMP directives) which can offer additional parallelisation within a subdomain. The basic working principle in OpenMP is based the “Fork-Join” model, as shown below.
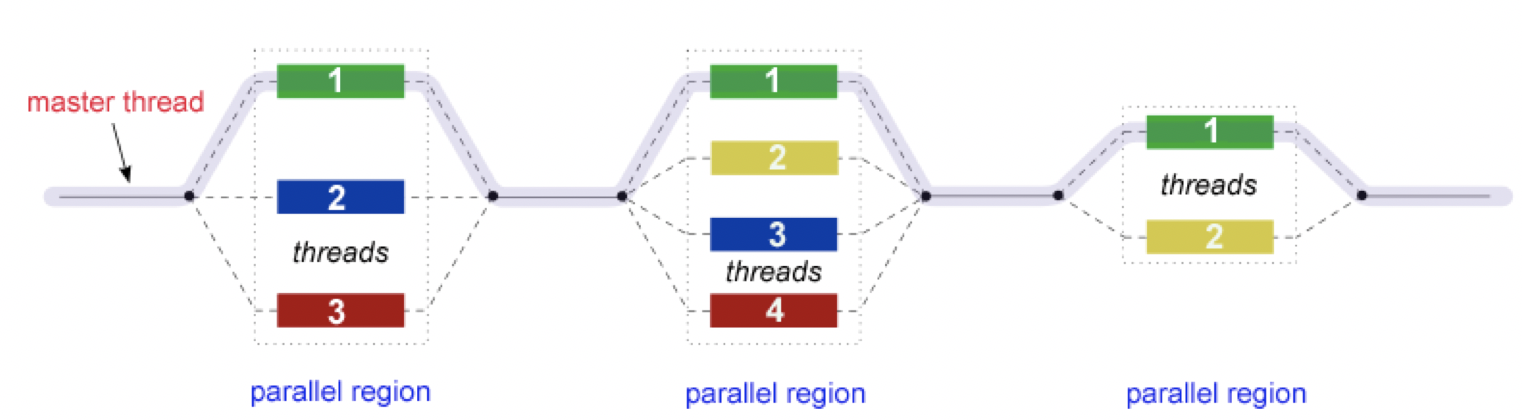
In the ‘Fork-Join’ model, there exists a master thread which “fork”s into multiple threads. Each of these forked-threads executes a part of the whole job and when all the threads are done with their assigned jobs, these threads join together again. Typically, the number of threads is equal to the number of available cores, but this can be influenced by the application or the user at run-time.
Using the maximum possible threads on a node may not always provide the best performance. It depends on many factors and, in some cases,the MPI parallelization strategy is so strongly integrated that it almost always offers better performance than the OpenMP based thread-level parallelism.
Another commonly found parallelization strategy is to use GPUs (with the more general term being an accelerator). GPUs work together with the CPUs. A CPU is specialized to perform complex tasks (like making decisions), while a GPU is very efficient in doing simple, repetitive, low level tasks. This functional difference between a GPU and CPU could be attributed to the massively parallel architecture that a GPU possesses. A modern CPU has relatively few cores which are well optimized for performing sequential serial jobs. On the contrary, a GPU has thousands of cores that are highly efficient at doing simple repetitive jobs in parallel. See below on how a CPU and GPU works together.
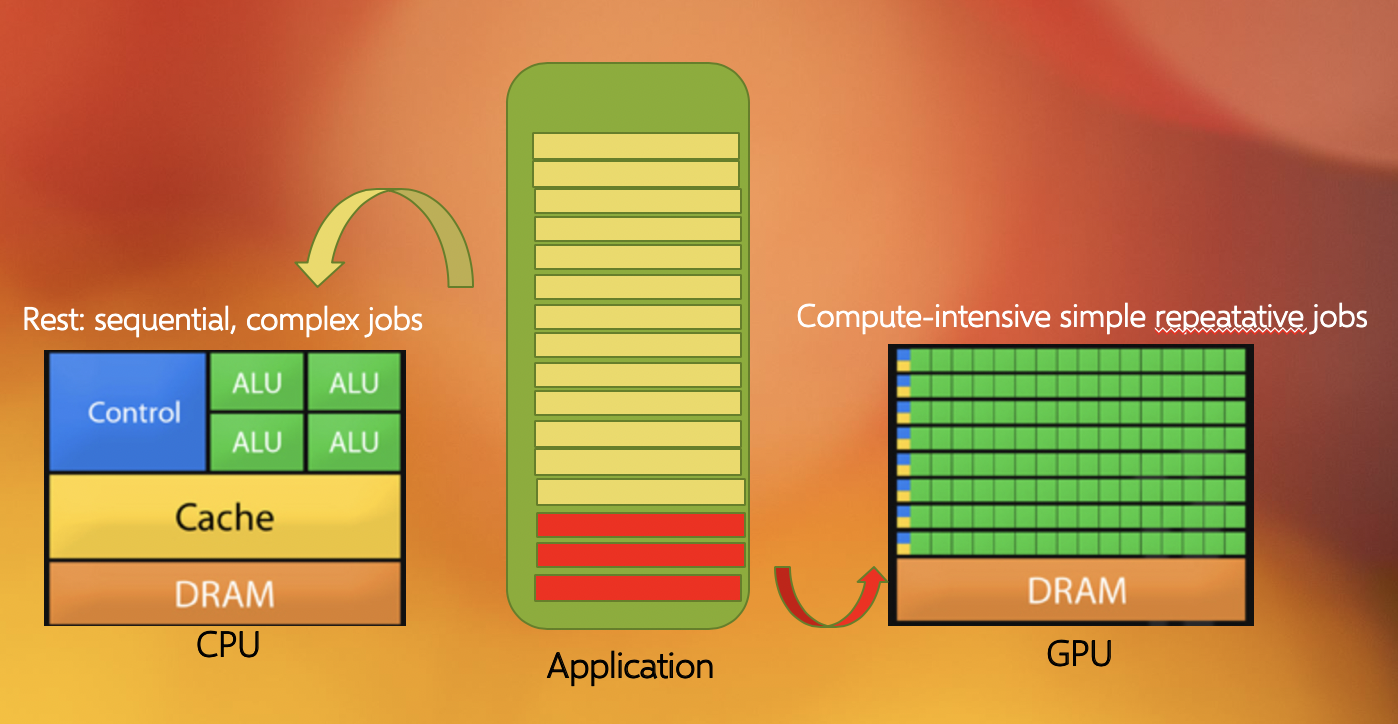
Using all available resources
Say you’ve actually got a powerful desktop with multiple CPU cores and a GPU at your disposal, what are good options for leveraging them?
- Utilising MPI (Message Passing Interface)
- Utilising OpenMP (Open Multi-Processing)
- Using performance enhancing libraries or plugins
- Use GPUs instead of CPUs
- Splitting code up into smaller individual parts
Solution
- Yes, MPI can enable you to split your code into multiple processes distributed over multiple cores (and even multiple computers), known as parallel programming. This won’t help you to use the GPU though.
- Yes, like MPI this is also parallel programming, but deals with threads instead of processes, by splitting a process into multiple threads, each thread using a single CPU core. OpenMP can potentially also leverage the GPU.
- Yes, that is their purpose. However, different libraries/plugins run on different architectures and with different capabilities, in this case you need something that will leverage the additional cores and/or the GPU for you.
- Yes, GPUs are better at handling multiple simple tasks, whereas a CPU is better at running complex singular tasks quickly.
- It depends, if you have a simulation that needs to be run from start to completion, then splitting the code into segments won’t be of any benefit and will likely waste compute resources due to the associated overhead. If some of the segments can be run simultaneously or on different hardware then you will see benefit…but it is usually very hard to balance this.
Key Points
OpenMP works on a single node, MPI can work on multiple nodes